Preface:
Link to GitHub: https://github.com/justingrisanti/dsc-capstone-project
Business Understanding
Context:
Spotify is an audio streaming and media services platfrom, created in 2006. It is one of the largest music streaming service providers with over 406 million monthly active users, including 180 million paying subscribers, as of December 2021. Spotify offers digital copyright restricted recorded music and podcasts, including more than 82 million songs, from record labels and media companies. As a freemium service, basic features are free with advertisements and limited control, while additional features, such as offline listening and commercial-free listening, are offered via paid subscriptions. Spotify is currently available in 180+ countries as of October 2021. Users can search for music based on artist, album, or genre, and can create, edit, and share playlists. Two of the most important aspects of Spotify that has led to its popularity are its music discovery functionalities, and playlist creation fostering a new social aspect to music listening. In a 2021 How-To Geek article called “6 Awesome Spotify Features You Should Be Using,” 3 of the 6 features are related to playlists, and one speaks about music discovery. One of these features related to music discovery is called “Enhance.” Enhance allows you to discover new tracks that might best fit one of your existing playlists. For example, if you have a playlist of a collection of 80s rock songs, Enhance might suggest that you add “Eye of the Tiger” by Survivor.
Business Problem:
Music is now one of the easiest forms of media to consume, due to smartphone technology allowing users to access millions of songs at their fingertips. However, with all of these choices, it is hard to know where to begin when it comes to finding new music that matches someone’s preferences, and users may become overwhelmed when trying to find music. The solution to this problem is to create a recommendation system from scratch that can reperform the functionality of Enhance, which is to use a selection of songs from a playlist and use content-based filtering to suggest a list of songs that are similar. The stakeholders of this project are Spotify, music-listeners, DJs, and other music-related occupations. The main purpose of this recommendation system is inferential, meaning that this model should be able infer information about songs from a given playlist and then to predict songs that a user will likely add to that same playlist.
Step 2: Data Understanding
We are sourcing our data using the Spotify Million Playlist Dataset, with the following metrics
- Number of playlists: 1,000,000
- Number of tracks: 66,346,428
- Number of unique tracks: 2,262,292
- Number of unique albums: 734,684
- Number of unique artists: 295,860
- Number of unique titles: 92,944
Our raw playlist data has the following features:
Playlist Attributes
- Playlist Name
- Playlist Type
- Number of Tracks
- Number of Unique Albums
- Number of Followers
- Number of Edits
- Duration in Milliseconds
- Number of Artists Song Attributes
- Artist Name
- Track URI
- Artist URI
- Track Name
- Album URI
- Duration in Milliseconds
- Album Name
As we see in the summary above, there are 1 million playlists with over 66 million songs. Within these playlists, there are 2.2 million unique songs, 734k unique albums, and 300k unique artists. There is a lot of data to work with here. The playlists are sorted into categories, with country and chill being the top, followed by rap and workout. Drake, Kanye West, and Kendrick Lamar are the 3 top artists. The next step in this process is to convert all of this json data to be compatible with python.
Note: For our data, we will select the top 100 playlists based on number of followers from 200k playlists due to runtime.
Step 3: Data Preparation
For our Content-Based model, we will compare 2 vectors using cosine similarity. The first vector will be our unique track data, with audio features, genre data, and popularity for each track, and the second vector will be a playlsit average vector, with average audio features, average genre data and average popularity by track.
Popularity and genre are self explanatory, but please see below for a guide to our audio features:
- Danceability: describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
- Acousticness: A measure from 0.0 to 1.0 of whether the track is acoustic.
- Energy: a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy.
- Instrumentalness: Predicts whether a track contains no vocals. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content.
- Liveness: Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live.
- Loudness: The overall loudness of a track in decibels (dB). Loudness values are averaged across the entire track. Values typical range between -60 and 0 db.
- Speechiness: detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value.
- Tempo: The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration.
- Valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
Step 4: Modeling
Our model is a content-based recommendation system using cosine similarity. I created a function that allows you to put in a playlist_id and number of recommendations desired, and then it provides that number of recommended tracks.
See below the three playlists selected for our reasonableness tests (102585, 765, 160101)
Reasonableness Test: 102585
Thank you for inputting your playlist. Please see playlist tracks below:
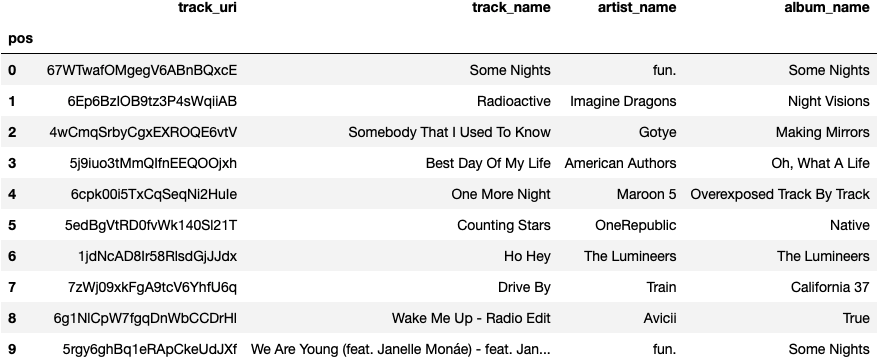
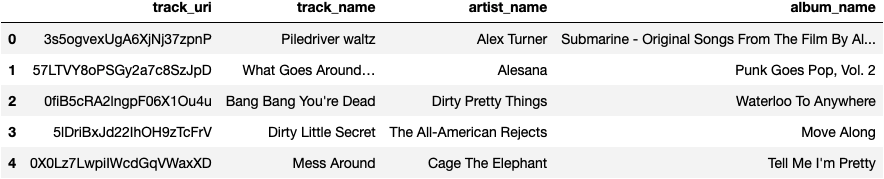
Here are 5 tracks that might fit this playlist:

As we can see above, the aggregate difference between our recommended songs and our playlist average is 14, which is driven mainly by the genre data. This metric is only useful when compared to other aggregate differences, so I will analyze when I review another playlist. While it can be argued that our genre data is so specific that it is dominating our model, I personally think the specificity of the genre helps us narrow our recommendations down to suggest more accurate songs.
Looking at our visualization, for the most part it appears that our features for our recommendations are comparable to the playlist, with Tempo driving the main difference.
Now for the sound test. I will document my subjective findings below: Some Nights, Radioactive, and Somebody That I Used to Know were all hits around 2013, and I personally have listened to these songs already. My description of Radioactive is an arena rock, bass thumping anthem that brings a high level of intensity. Some Nights and Somebody That I Used to Know are more chill and have a very nostaglic sound to them.
For our recommendations, What Goes Around…, Bang Bang You’re Dead, Dirty Little Secret and Mess Around are all alternative/rock sounding tracks, whereas Piledriver Waltz is definitely more on the chill side.
Overall, based on our genre analysis and feature comparison, I would deem that these 5 recommended songs pass the reasonableness test.
Reasonableness Test: 765
Thank you for inputting your playlist. Please see playlist tracks below:
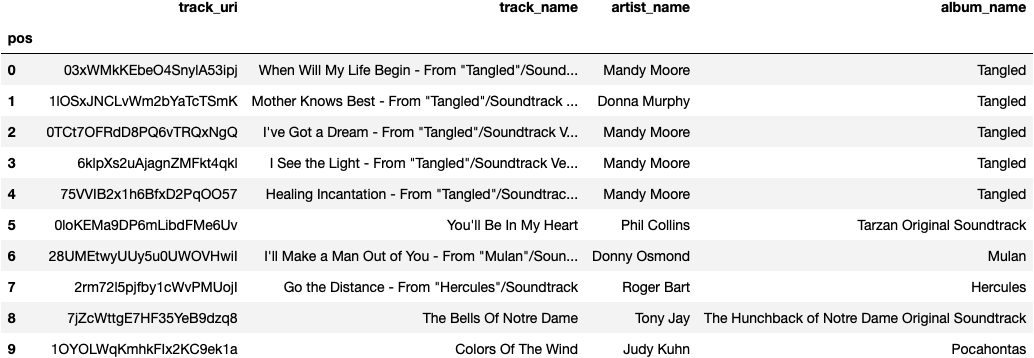
Here are 10 tracks that might fit this playlist:
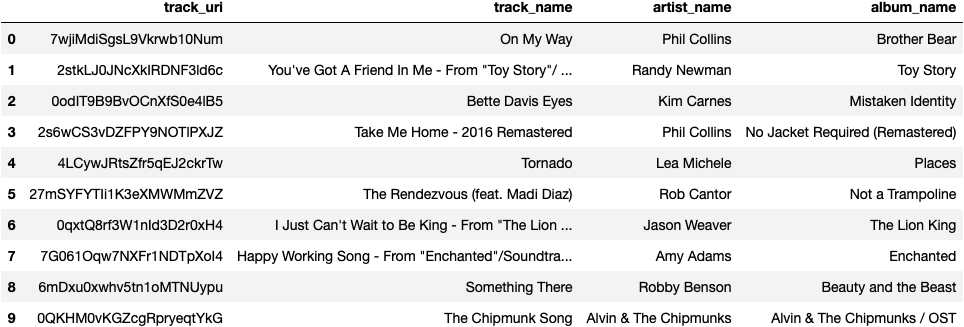
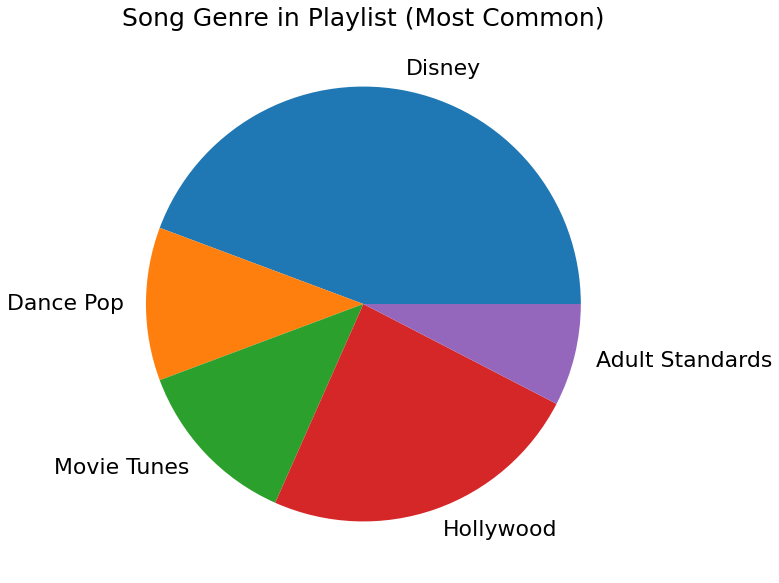
As we can see above, the aggregate difference between our recommended songs and our playlist average is 6, which is driven mainly by the genre data. Most of our songs here are Disney/Soundtrack, so there seems to be little variation here. This aggregate difference is better than our first playlist, although it seems our features may be offsetting some of that difference.
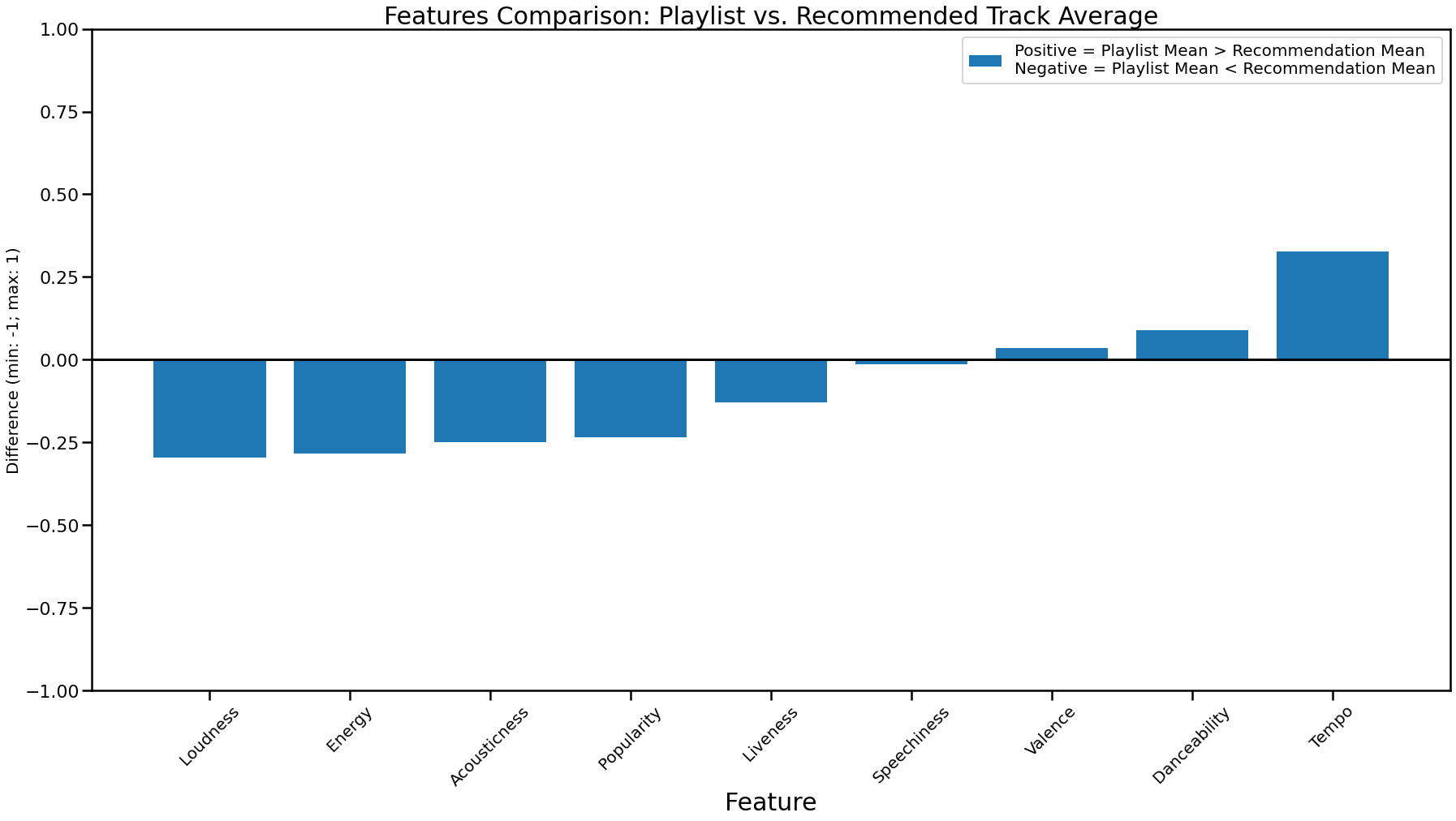
Looking at our visualization, for the most part it appears all of the features are comparable, with teempo, energy, popularity, loudness and danceability having the largest difference. Seeing that the general theme of this playlist seems to be soundtrack for childrens movies, I believe that genre is the most important driver of the recommender here, and it seems like our genre hit the mark.
Now for the sound test. I will document my subjective findings below: As we can see from our selection of songs, they all seem to be Disney songs from Moana and Tangled. I would expect that our recommendation system would suggest other kids songs accross childrens movies. After pulling more songs from the unwrapped track data, I can confirm that there are some songs that are not Disney.
For our recommendations, all 10 songs appear to be soundtrack songs, which is great, and they are all mainly from beloved kids movies. Because it seems like kids movies is the main category for this playlist, I will deem this recommendation adequate.
Overall, I would deem that these 10 recommended songs pass the reasonableness test.
Reasonableness Test: 160101
Thank you for inputting your playlist. Please see playlist tracks below:
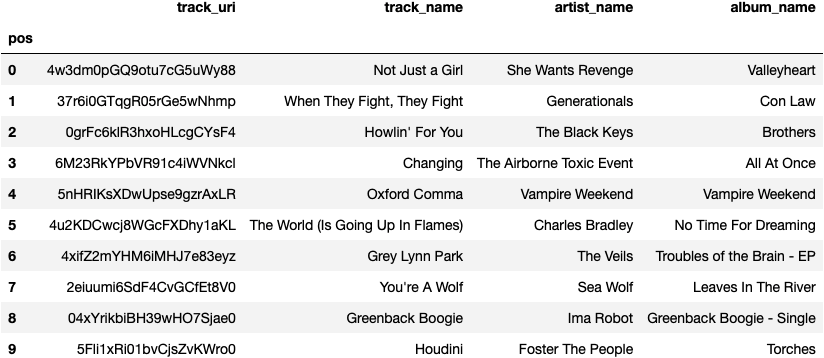
Here are 5 tracks that might fit this playlist:
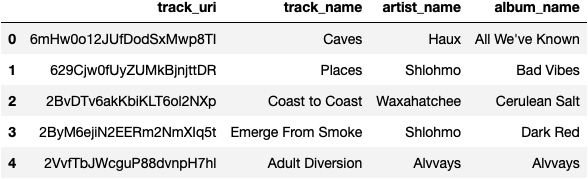
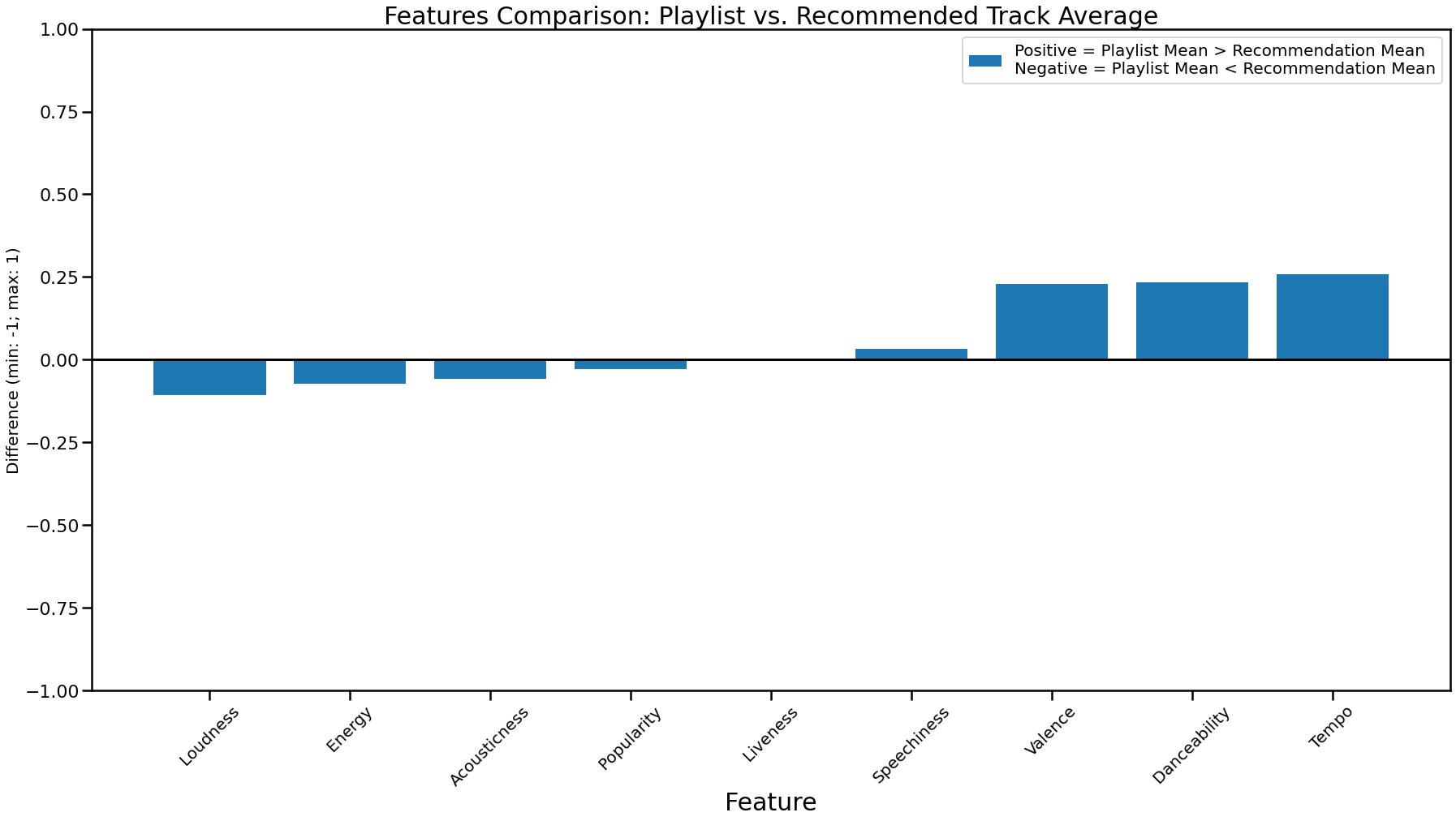
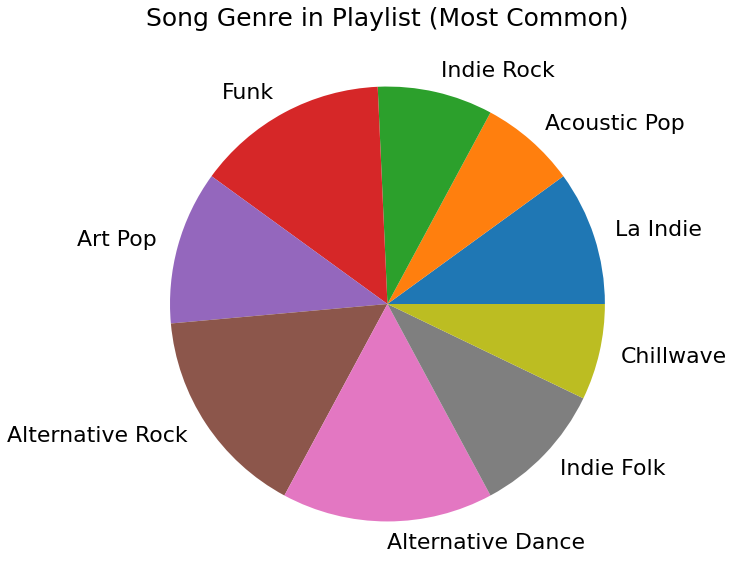
As we can see above, the aggregate difference between our recommendations and our playlist data is pretty large, at 44. I believe this is driven by our genre data, as it is very evenly spread our across multiple genres
According to our feature visualization, our differences are very minimal compared to the other playlists. The largest differences are Speechiness, Acousticness and Energy.
Now for the sound test. I will document my subjective findings below: From our playlist, I already recognize M83, the Black Keys and Vampire Weekend. Outro by M83 is very spacy and slow, whereas Howlin’ For You is more uptempo and rock themed. Oxford Comma is also uptempo and kind of spaced out, but overall sounds chill. Not Just a Girl is slower paced, but also sounds like alt-rock overall. For our recommendations, I would expect chiller alt-rock that is slower in pace and has mostly fleshed out instrumentals.
For our recommendations, I recognize none of the songs. Caves, Coast to Coast and Diversion are very Indie sounding, somewhat Alternative. The two songs by Shlohmo are dance-like, and sound more electronic. They are also instrumentals. Outro by M83 fits a similar vibe to these songs.
This playlist seems like there is more variety between the genres, and as such, my recommendations also seem varied. However, due to the feature difference being relatively small, and due to the genres fitting the broad scope of the playlist, I deem these recommendations sufficient.
Step 5: Results
To summarize: using cosine similarity, I was able to successfully create a recommendation system using a selection of data from the Spotify Million Playlist Dataset. Overall, I have identified 3 potential drawbacks that might affect this model: 1. Suggesting songs from the same basket that the machine is learning from may create bias, 2. There are few metrics to assess our system, which makes it harder to determine the broader success of the model, 3. I analyzed the model using subjectivity. Tastes can be very different and subjectivity begets bias, as well. With these in mind, however, I beleive that this recommendation system is adequate at suggesting similar songs based on our tests in the results section.
As shown in the results section, our music recommendations seem to be driven mainly by the genre. Extracting Genre data from Spotipy provided us with very specific genre data that might’ve been able to isolate our list to a very select handful of songs. It then used the audio features and popularity vectors to differentiate the songs when it came to using cosine similarity.
I believe some good improvements to this project would be to source more general genre data if it is eventually made available as an export from Spotipy. As I had to manually export the data from Spotipy usng different means, it is hard to tell how accurate the genre data actually is. I would also like to include information on the year released, in case a playlist is related to a certain year, for example, 2013s hits. I would also like user-review data that shows how much a user liked a song, so I could try a collaborative-based filtering approach. Another thing I would like to do is research other forms of content-based recommendation systems, perhaps some form of clustering. Lastly, if I had a faster computer I would include all of the playlists in my analysis to capture more songs for my recommendation system.